Spartan Finally Receives Its Laurels
 Way back in 2015 the University of Melbourne had a general-purpose high performance computer system called "Edward", which itself replaced an even smaller system called "Alfred", both named after the Kings of Wessex. Edward was a fairly typical machine for its vintage and, as is normal, when a system is being retired the main researchers were asked what should be different in the new system. What was also normal was their answers; more cores, faster CPUs, etc. Consideration was given to not having an HPC system at all, potentially offloading the demand to a national facility. But cooler heads that possibly understood network throughput and the advantages of fine-tuning a local system to the needs of local researchers prevailed.
Way back in 2015 the University of Melbourne had a general-purpose high performance computer system called "Edward", which itself replaced an even smaller system called "Alfred", both named after the Kings of Wessex. Edward was a fairly typical machine for its vintage and, as is normal, when a system is being retired the main researchers were asked what should be different in the new system. What was also normal was their answers; more cores, faster CPUs, etc. Consideration was given to not having an HPC system at all, potentially offloading the demand to a national facility. But cooler heads that possibly understood network throughput and the advantages of fine-tuning a local system to the needs of local researchers prevailed.
One of the interesting things about the review of Edward's utilisation was how it differed from what many researchers thought they needed. Rather than a system with more cores etc, what was really needed was faster throughput. Researchers simply didn't like their jobs sitting in the queue. Coupled with the fact that finances to fund the system weren't great (the naming of Spartan was a laconic reference to its lean cost-efficiency), necessity became the mother of invention. The Nectar research cloud had plenty of cores and, according to the metrics, the overwhelming majority of Edward's jobs were being run for capacity, rather than capability; over 75% were single-core jobs and over 90% were single-node jobs. Rather than spend a lot of money on high-speed interconnect, which is typical in HPC systems, a decision was made to have a smaller traditional HPC partition ("physical") and use a partition virtual machines ("cloud") with a slow interconnect for those singe-node jobs.
It was an innovative design and received a well-deserved initial launch, followed by a world-tour explaining the architecture to various conferences and HPC centres, including Multicore World, Wellington, 2016, and 2017; eResearchAustralasia 2016, Center for Scientific Computing (CSC) Goethe University Frankfurt, 2016, High Performance Computing Center (HLRS) University of Stuttgart, 2016, High Performance Computing Centre Albert-Ludwigs-University Freiburg, 2016; European Organization for Nuclear Research (CERN), 2016, Centre Informatique National de l’Enseignement Supérieur, Montpellier, 2016; Centro Nacional de Supercomputación, Barcelona, 2016, and the OpenStack Summit, at Barcelona 2016, and featured in OpenStack and HPC Workload Management in Stig Telfer (ed), "The Crossroads of Cloud and HPC: OpenStack for Scientific Research" (Open Stack, 2016).
The success of Spartan's architecture soon became apparent. Whilst Edward had completed just over 375,000 jobs in 2015, Spartan completed more than a million in its first year from launch. The system expanded with additional compute nodes from specialist projects, departments, and research agencies that had purchased their own hardware. But the most significant expansion was the addition of a substantial GPGPU partition, of 68 nodes and 272 nVidia P100 GPGPU cards, funded by a Linkage Infrastructure, Equipment and Facilities (LIEF) grant. Later, Spartan also introduced FastX for interactive remote desktops, and interactive sessions through Open OnDemand for Jupyer notebooks, RStudio, and Cryosparc.
The introduction of the GPGPU partition really transformed Spartan. It was what changed Spartan from being a small, experimental, but extremely successful system, to a world-class computing system. At the time we estimated that it would have entered at c200 on the top500.org list. However, running the tests to enter into that celebrated list requires both a lot of fine-tuning and, of course, it means that users, which have priority on our system, won't be able to use the nodes. On Spartan, it is typical that 100% of workers nodes are fully allocated, so for literally years there was little opportunity for the tests to be conducted.
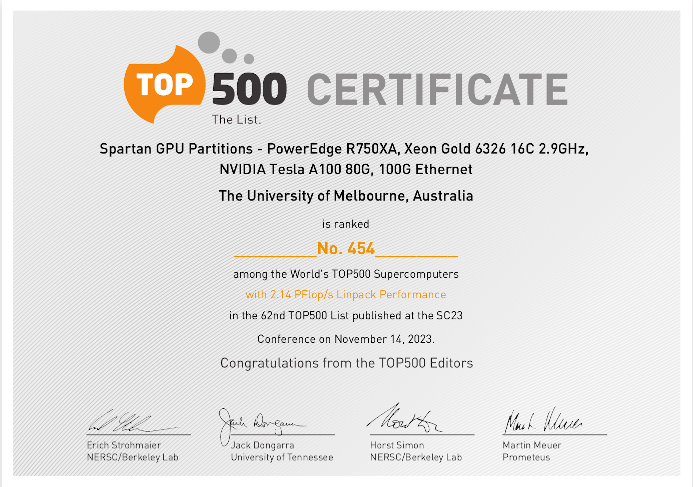
Recently however, Spartan finally took the leap to change from running RedHat 7.x, which we had been doing since 2015, gradually working our way up the point-released, to RedHat 9.x. This provided a well-advertised two-week window of opportunity and whilst many other changes occurred to the operating system, the hardware, and the recompilation of hundreds of applications, a work colleague, Naren Chinnam (with necessary coordination with the rest of the HPC, Network and DC teams in getting the cluster stable enough for the benchmarks to finish), completed the LINPACK test for part of the system. As a result, Spartan now has a nice certificate, rated at 454 in the world (and third in Australia, after NCI/Gadi and Pawsey), with a benchmark score of 2.14 PetaFlops, representing the performance of the GPU partitions alone. It has already been noted that we actually have 88 A100 GPU nodes, not the 72 that were tested, which would have brought us up to 337 in the world, plus another 1/3rd of our performance could have come from the CPU-only partitions.
At the time of writing, Spartan has run 53881908 HPC jobs. There are 6134 users from the University of Melbourne and around the world, across 2097 projects. The original architecture (with our friends at the University of Freiburg with their alternative cluster-cloud combination) was also featured at the IEEE 13th International Conference on e-Science in 2017, and in the Science, Technology and Engineering Systems Journal in 2019, with other presentations on Spartan including use of the GPGPU partition at eResearch 2018, its development path at eResearchAU 2020, interactive HPC at eResearchNZ 2021, and over 250 papers citing Spartan as a contributing factor their research. Spartan continues to grow in users, usage, performance and, most importantly, research outcomes. Spartan may have finally received its laurels, but we are not resting on them.
| Attachment | Size |
|---|---|
| 367.83 KB |